Speech-to-Text Accuracy: Why 95% Word Accuracy Still Fails You
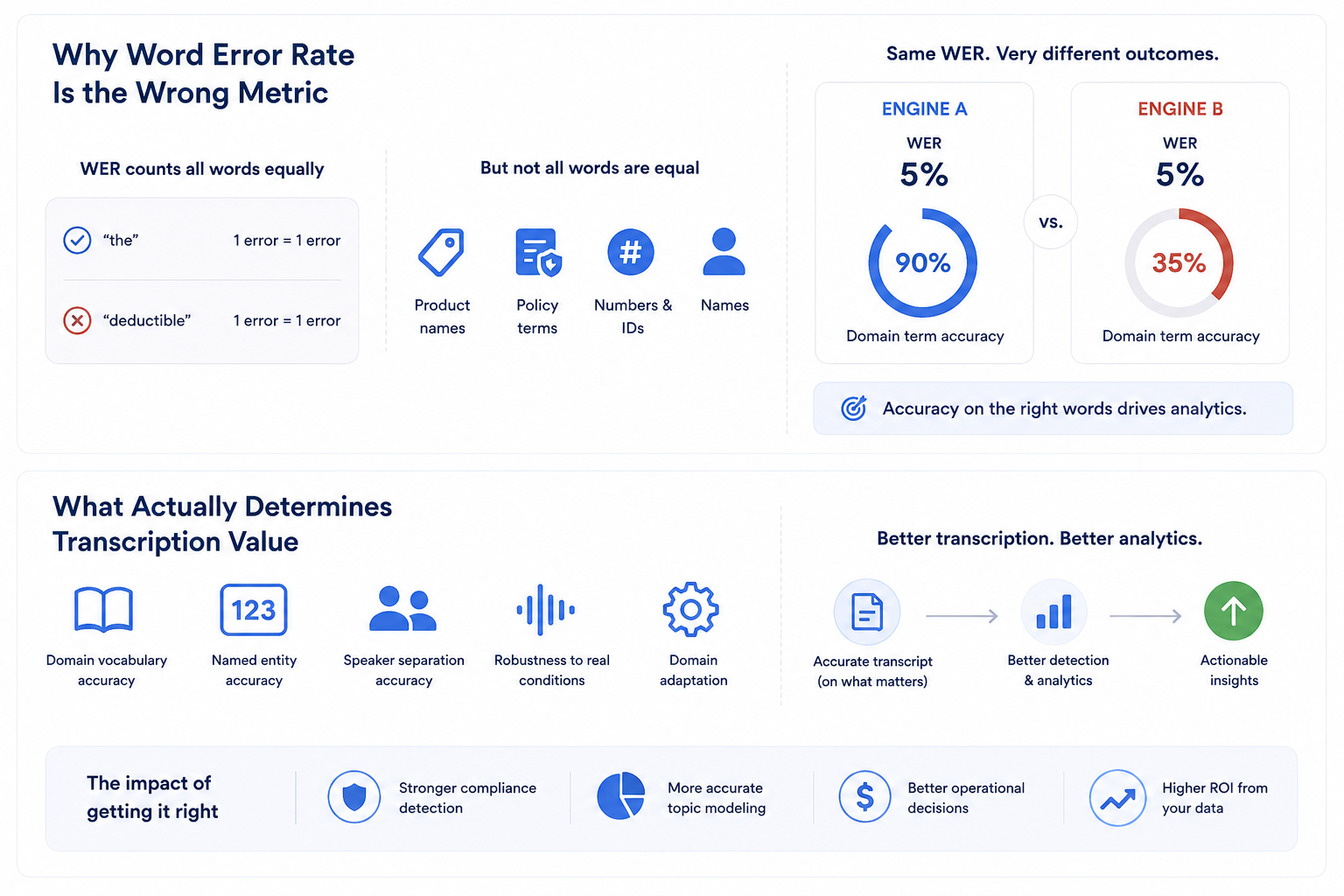
An insurance contact center we workedwith had evaluated a speech-to-text vendor on a single number: word error rate.The vendor benchmarked at 5% WER, meaning 95% word accuracy, which beat thecompetition and won the deal. Six months in, the analytics team was frustrated.The transcripts looked accurate but the downstream analytics — compliancedetection, topic categorization, sentiment — were performing worse thanexpected.
We dug into the failures. The 5% of wordsthe engine got wrong weren’t randomly distributed. They were concentratedexactly where it mattered: product names, policy terms, proper nouns, numbers,and the domain-specific vocabulary that the analytics depended on. The enginenailed the common words — “the,” “and,” “I’d like to” — and missed“deductible,” “rider,” “underwriting,” and the specific product SKUs. 95% wordaccuracy, and near-zero accuracy on the words that carried the meaning.
This is the trap of evaluatingspeech-to-text on word error rate. WER treats every word as equally important.In a contact center, the words are catastrophically unequal in importance, andthe engine that wins on WER often loses on the only accuracy that matters.
WER counts the percentage of words transcribed incorrectly, treatingall words identically. A missed “um” costs the same as a missed policy number.For general transcription this is reasonable. For contact center analytics it’sactively misleading.
The reason is that the value of a transcript isn’t in its words —it’s in what you do with it. If you’re running compliance detection, the onlywords that matter are the ones tied to the compliance requirement. If you’recategorizing call topics, the only words that matter are the topic signals. Ifyou’re detecting product mentions for cross-sell analysis, the only words thatmatter are the product names. WER averages across all words and tells younothing about accuracy on the words your use case depends on.
This is why two engines with identical WER can produce wildlydifferent analytics performance. The one that’s accurate on common words andweak on domain vocabulary will benchmark identically and perform far worse inproduction.
For contact center speech analytics, several accuracy dimensions matter more than aggregate WER.
Domain vocabulary accuracy. How well does the engine handle yourindustry’s specific terms, your product names, your acronyms? This is usuallythe single biggest determinant of analytics quality and it’s completelyinvisible in a generic WER benchmark.
Named entity accuracy. Numbers, names, dates, amounts, accountreferences. These carry disproportionate meaning and are disproportionatelyhard for general engines, which are trained on conversational speech wherethese appear less frequently.
Speaker separation accuracy. In a two-party call, knowing who saidwhat is often as important as what was said. A compliance disclosure onlycounts if the agent said it. An engine that transcribes accurately butattributes poorly is useless for agent-level analytics.
Robustness to real conditions. Accents, background noise, telephonycompression, crosstalk, emotional speech. Benchmark WER is usually measured onclean audio. Production audio is messy, and the accuracy gap between clean andmessy conditions varies enormously between engines.
The biggest lever on transcription accuracy for a specific contactcenter isn’t the base engine — it’s adaptation to the specific domain.
A general engine handles general speech well. A general engineadapted to your vocabulary, your products, your acronyms, and your typical callpatterns handles your calls dramatically better. The accuracy improvement fromdomain adaptation on the words that matter often dwarfs the difference betweencompeting base engines.
This is why the procurement question “what’s your WER” is the wrongquestion. The right questions are: how does the engine adapt to our domain, howquickly, and what’s the accuracy on our specific high-value vocabulary afteradaptation. Vendors who lead with WER are usually answering the question thatflatters them, not the one that predicts your outcome.
1. Build a domain vocabulary testset. List your 50 most important terms — products,policy language, compliance phrases. Test your current engine’s accuracyspecifically on these. The result will likely differ sharply from the headlineWER.
2. Audit speaker separation accuracy. Pull 20 transcripts and check whether agent and customer turns arecorrectly attributed. Agent-level analytics depend entirely on this.
3. Test on your worst audio, not yourbest. Evaluate accuracy on heavily accented calls,noisy calls, and emotional calls. That’s where the engines separate.
4. Trace one analytics failure back tothe transcript. When compliance detection or topiccategorization misses, check whether the root cause was the transcript. Itoften is, and it’s usually a domain-vocabulary miss.
5. Ask vendors about adaptation, notWER. How does the engine learn your vocabulary, howfast, and what accuracy does it reach on your terms specifically. The answerpredicts your outcome better than any benchmark.
A transcription engine that’s 95%accurate on words and 40% accurate on the words you actually need is worse thanuseless — it’s confidently wrong in exactly the places you’re relying on it.Word error rate measures the easy part. The hard part, and the valuable part,is the vocabulary your business runs on.

The AI terminology chaos is real. Your "divide and conquer" framework is the clarity we needed.

Finally, a clear way to cut through the AI hype. It's not about the name, but the problem it solves.

