Why Contact Center QA Programs Fail to Improve CSAT Scores and How to Fix Them
Contact center quality assurance monitors, evaluates, and improves customer conversations to maintain service standards you can actually measure. Here's the thing though - most QA programs connect agent behavior to business results like customer satisfaction and retention in theory. In practice? That connection breaks down fast.
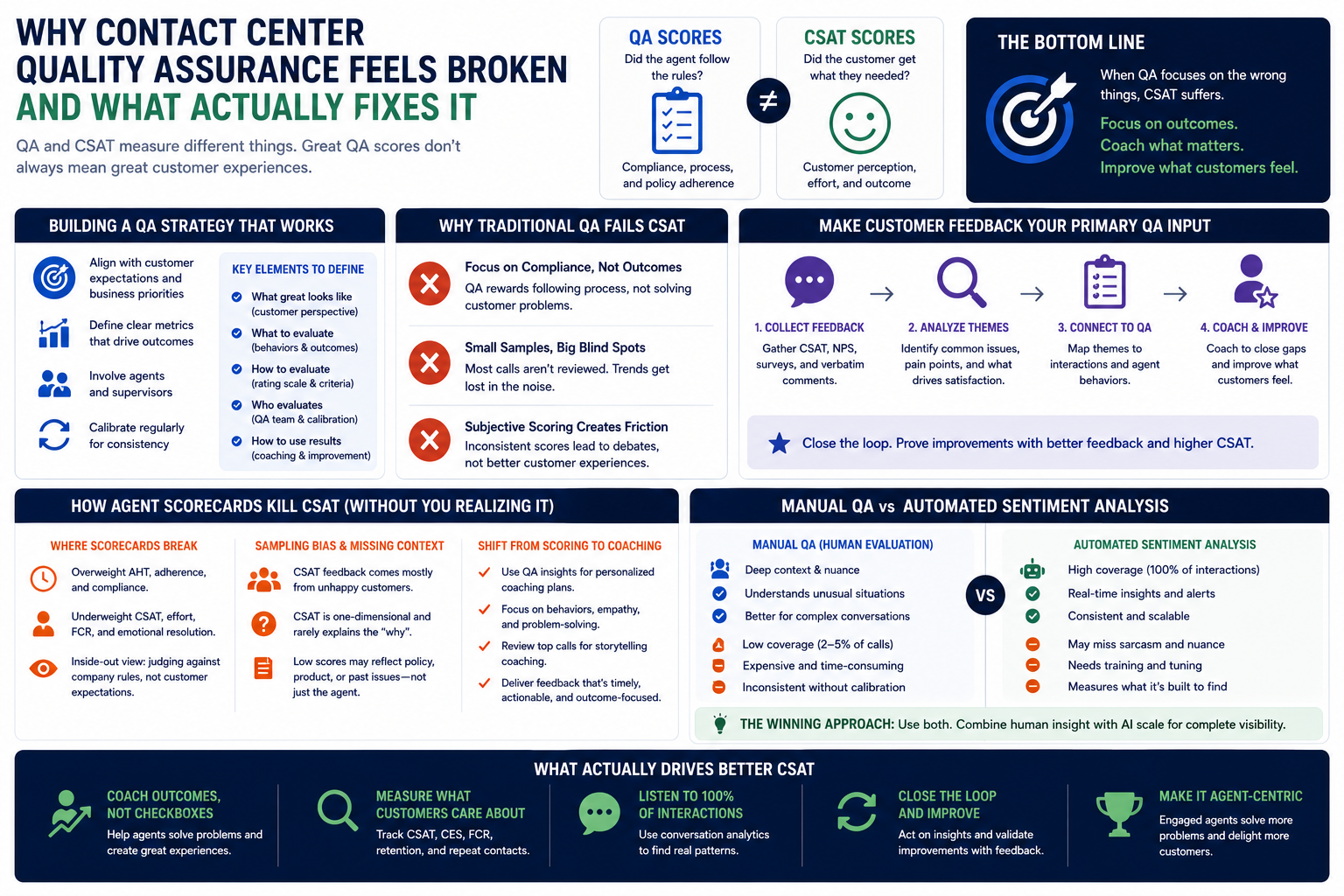
QA scores show whether agents followed company policies. Did they greet customers correctly? Read the compliance script? Follow the rules? CSAT scores reveal something completely different - how satisfied customers felt with their experience.
Both metrics aim to improve customer interactions, but they measure totally different things. And that disconnect? It's the root of most contact center quality problems.
Effective QA programs go way beyond scorecards. You need a clear strategy with defined metrics, then tie those numbers to coaching opportunities and what your business actually prioritizes.
Here's what to define:
Get agents and supervisors involved in developing your QA program. This creates buy-in and ensures the program reflects real customer expectations. Run regular calibration sessions so different evaluators apply consistent standards to identical interactions.
Without calibration, scores drift all over the place. Coaching becomes arguments about numbers instead of plans for improving customer interactions.
Traditional QA aims for service quality, but the methods often miss the mark on customer satisfaction entirely.
Traditional QA fails because it measures compliance and observable behaviors more consistently than whether customers got what they needed. That gap explains why QA scores don't reflect customer satisfaction in most contact centers. When leaders treat high QA scores as proof of great experiences, improvement efforts drift away from what customers actually value.

A QA evaluator can score an interaction highly for following protocols, staying professional, and communicating clearly. Meanwhile, the customer still feels unresolved or misunderstood.
The reverse happens too - agents might deliver fantastic customer experiences but break internal rules to do it.
Traditional scoring rewards "did the process happen" more than "did the customer outcome happen."
Both QA and CSAT scores reflect small sample sizes because most contact centers can't audit every call. Small samples create noise and make trends unreliable, especially when you're basing coaching decisions on a handful of monitored interactions.
Subjective categories like empathy create unproductive conversations about scores rather than behaviors. If coaches can't define what "good" looks like in observable terms, coaching becomes inconsistent and agent improvements stall. This is where contact center QA skills matter - calibration, behavior-based scoring, and coaching tied directly to measurable outcomes.
Want contact center QA to improve customer satisfaction? Use direct customer feedback as your primary input, not an afterthought. Start with CSAT, NPS, and surveys, then map customer feedback to agent performance at the interaction level.
Simple workflow:
Agent scorecards contribute significantly to this disconnect.
Agent scorecards often fail to lift CSAT because they're built for internal inspection, not customer perception. This creates QA program gaps contact center leaders miss - quality assurance and customer satisfaction move in opposite directions when QA scores reward brand standards over lived experience.
Traditional forms over-index on operational KPIs like average handle time, script adherence, and compliance rates. They underweight customer-centric KPIs like CSAT, customer effort score, and first contact resolution.
The inside-out problem shows up when you evaluate customer interactions against company standards, while customer expectations focus on communication clarity, professionalism, and emotional resolution.
Customers who leave CSAT feedback tend to be those who had the worst experiences - sampling bias. CSAT is one-dimensional and rarely explains what needs fixing. Low CSAT might reflect policy limits, product issues, or prior frustrations, not just the agent interaction.
Manual QA is subjective and covers tiny samples, so use QA insights for personalized agent coaching plans. Focus on behavior-based actions, protocol adherence, and empathy guidance. Review high-scoring calls for storytelling coaching, then deliver feedback that's timely and actionable, mapped from customer feedback to agent performance and coaching gaps.
The evaluation method itself plays a crucial role in understanding customer sentiment.
Manual scoring and automated sentiment analysis solve different problems. Confusing them commonly drives low CSAT despite high QA scores. Manual QA (human evaluation of selected interactions) surfaces nuanced coaching opportunities but rarely scales. Automated QA and sentiment tools monitor more interactions, but many systems measure what's easiest to count, not what changes customer expectations.

Manual QA excels at interpreting context in agent interactions - communication clarity, situational professionalism, and whether following protocols made sense for the customer.
Manual QA also has predictable failure modes:
Assign one owner for calibration sessions (often the QA lead) and one owner for coaching follow-through (team leads), or insights stall.
Automated QA provides value through scale and objectivity - near 100% interaction coverage in many deployments and consistent checks for repeatable events. The risk? Most automated QA solutions prioritize quantity over quality, measuring superficial compliance rather than driving meaningful improvement.
Some platforms automate the worst parts of QA - checklists, box-ticking, and punitive measures that demoralize employees while adding little strategic value.
AI and speech analytics can detect if an agent said "Is there anything else I can help you with?" But AI can't reliably determine whether the phrase landed with empathy or frustration. Voice of Customer sentiment models optimize for broad sentiment and themes, not detailed compliance and process adherence. VoC trends help connect QA metrics to business outcomes, but they typically lack multi-criteria precision needed for individual agent performance scoring.
ApproachBest forKey limitation---------Manual QADeep coaching, edge cases, interpreting intentCost, bias, small samplesAutomated QAScalable monitoring, consistent rule checksCan reward superficial complianceSentiment analysisExplaining the "why" behind dissatisfactionTrend-level, not agent-level precisionHybrid modelCombining scale with human judgmentRequires clear governance and review queues
To truly improve CSAT, contact centers must adopt practices that bridge internal quality and external customer perception.
Contact center QA improves CSAT only when the program measures what customers actually experience and turns findings into repeatable behavior change. The goal is tight alignment between QA criteria and customer expectations, so quality scores and CSAT move in the same direction. Treat QA as an operating system (strategy, workflow, calibration, coaching), not a scorecard.
Start with a one-page plan defining what "good" means for your customers, then translate that into observable behaviors and outcomes. This is where QA best practices become operational, not aspirational.
Key elements your plan should enforce:
If the QA form rewards "professionalism" but ignores resolution clarity, agents can optimize for points without improving customer outcomes.
Involve frontline agents and supervisors in defining evaluation criteria and examples of "meets expectations" versus "misses expectations." This reduces debates about subjective items like empathy and improves adoption because the team recognizes the standard as fair.
Assign one QA lead to facilitate, one supervisor per channel to validate feasibility, and rotate two high-performing agents to pressure-test language for clarity.
Use multiple perspectives to avoid single-method bias, especially when comparing manual QA versus automated sentiment analysis.
Manual review catches nuance in agent interactions, automated analysis scales coverage. Use both, then reconcile conflicts in calibration.
Convert findings into targeted coaching opportunities and team learning loops. Use QA trends to inform coaching and training by mapping recurring misses to skills, then assigning practice and follow-up checks in the next evaluation cycle.
Common questions about customer satisfaction and its measurement persist even with improved QA practices.
Contact center QA programs usually fail to move CSAT because the program can't explain, in a repeatable way, which parts of an agent interaction change customer expectations. When teams treat QA as scoring instead of diagnosis, agent scorecard limitations turn quality monitoring into a compliance exercise, not a customer outcome engine.
If contact centers don't have fundamentals in place first, they won't drive sustained improvement with automated solutions. Foundations for effective QA include establishing root cause analysis cycles and continuous identification of predictive, proactive actions. If a contact center isn't getting it right with 0.5% of customer contacts currently monitored, automating the process won't fix problems.
Make one owner accountable for turning monitoring customer interactions into actions, then verifying consistent service quality week over week.
Next, we'll cover fixing QA blind spots with sentiment data.
Sentiment analysis is a practical way to expose where traditional QA frameworks misread customer expectations, even when internal scores look strong. Use sentiment as an evidence layer on top of QA so you can see which parts of an agent interaction actually predict CSAT movement. The target state is simple: QA scores and CSAT scores closely correlate, with both at or above goal.
Treat sentiment as directional, not a verdict, because context matters. "Polite" language can still fail if customer expectations are speed and clear next steps, so coaching must prioritize improving customer interactions, not polishing scripts.
Next, we'll answer frequently asked questions about QA and customer satisfaction.
Not necessarily. Many organizations assume expanding monitoring customer interactions will directly improve CSAT, but better monitoring doesn't guarantee better customer outcomes. Correlation doesn't imply causation - a QA to CSAT relationship can only suggest where to look.
Customer satisfaction ratings are directionally helpful, but they're not actionable on their own. Pair CSAT with specific interaction evidence before changing coaching or policy.
Many QA leaders use a practical "5 Ps" checklist to keep quality assurance in contact centers operational, not theoretical: Purpose, Process, People, Performance, and Proof.
If "Proof" is missing, you can end up with contact center quality assurance problems like higher QA scores with flat CSAT.
The 80/20 rule is a prioritization mindset: focus QA effort on the small set of behaviors or contact types that drive most dissatisfaction. This is especially useful when agent scorecard limitations hide what customers actually react to.
Prioritize high-impact failure points such as unclear next steps, weak ownership language, or broken handoffs.
Improve QA by tightening the link between what you score and what customers feel, using a blend of manual QA versus automated sentiment analysis. Fixing QA blind spots with sentiment data helps you see where the scorecard misses customer expectations, then target coaching to observable behaviors.
Assign QA leads to define behaviors, and team leads to reinforce them in weekly coaching.
Transforming QA into a CSAT driver requires a strategic shift in focus and methodology.
Traditional contact center quality assurance problems persist because programs reward internal checks, not customer outcomes. This explains why QA scores don't reflect customer satisfaction and creates low CSAT despite high QA scores. Making sure your Quality Program correlates to the customer experience is the foundation, because Customer Satisfaction is the "VOICE" of the customer and clarifies customer expectations: customers need resolution and to be treated as a person, not a transaction.
Define a QA strategy plan with agent performance and KPIs, and validate that call center QA metrics track CSAT so contact center QA improves customer satisfaction.
Close QA program gaps contact center teams miss by involving agents and supervisors early, and by running regular QA calibration sessions to ensure consistent service quality when monitoring customer interactions and evaluating customer interactions.
Address agent scorecard limitations with QA best practices: self-assessment, peer review, and manual QA versus automated sentiment analysis using conversational intelligence for scalable QA (for coaching opportunities, communication clarity, protocol adherence, and professionalism), including fixing QA blind spots with sentiment data and building the skills for call center quality assurance into daily coaching.
Next, prioritize the program changes that will measurably improve customer interactions and CSAT.

The AI terminology chaos is real. Your "divide and conquer" framework is the clarity we needed.

Finally, a clear way to cut through the AI hype. It's not about the name, but the problem it solves.

